exFAT data recovery
Posted on April 15, 2023 • 15 minutes • 3144 words
A simple mistake
While testing the effectiveness of a faster SD card on NixOS build times, I overwrote the first 16 GiB of my PSVita SD card. Without going into the specifics, I made a typo and lost the backup of those first 16GiB.
This could’ve been avoided by making the backup image readonly:
$ chmod -w vita.img
$ dd if=/dev/sdi of=vita.img
dd: failed to open 'vita.img': Permission denied
Recovery
The SD card is relatively large at 256GiB, however most of that is dumped games. I do have a backup from a week ago, so all that I am missing is a couple save games.
Assuming not much fragmentation occurred, these should be somewhere in the middle of the data, so losing the first 16 GiB likely didn’t damage anything important. However, the first few sectors of exFAT holds crucial information.
What even is exFAT?
exFAT is a filesystem which stands for Extensible File Allocation Table, the file allocation table is how it deals with fragmentation. A filesystem is nothing more than a specification of how to interpret one contiguous block of data as separate files, luckily Microsoft made the specification public in 2019. Microsoft’s docs are pretty awful to navigate so I would recommend the docs on ChaN’s site: http://elm-chan.org/docs/exfat_e.html
You might have wondered what the sector size is when formatting a drive, essentially it’s the size of the blocks that the filesystem works with (exFAT calls them clusters, but I will keep calling them blocks). Any file larger than that needs to be split up across multiple blocks (this is called fragmentation).
The blocks are either data from a file or metadata. There are multiple kinds of metadata, but I’m only interested in directory listings - which contain a list of files/directories, and where to find them. While it’s technically impossible to tell metadata blocks apart from actual file data, file data is unlikely to be valid metadata, especially since the save data is encrypted (thanks Sony).
The root directory of the filesystem is a directory listing, it’s usually found near the beginning of the drive, so it is most certainly missing from my data.
Guessing the sector size
The size of the blocks is at the beginning of the drive, along with other important information about the filesystem. However, it can be guessed by looking at the data.
I found a metadata block in ImHex , after it ends there are a bunch of zeros, and the next block looks like the start of a PNG file:
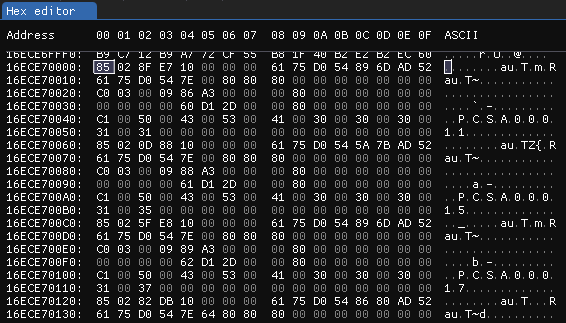
A metadata block
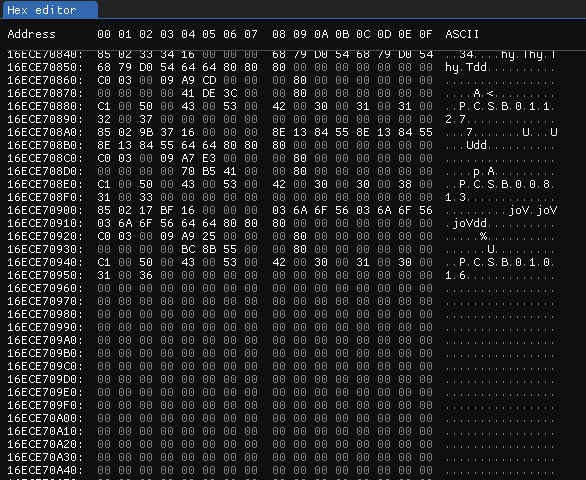
The end of the metadata block's data
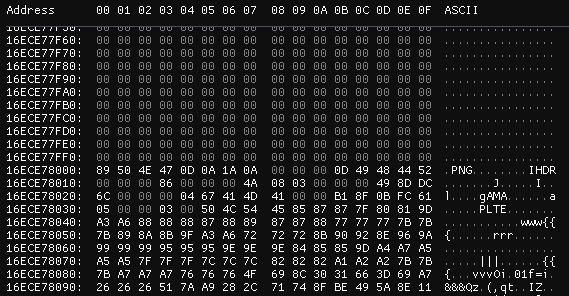
The start of the next block
This lets me calculate the block size of the filesystem:0x16ECE78000 - 0x16ECE70000 = 0x8000 (32 KiB)
This also means that any files above 32 KiB may have been fragmented, which could make them unrecoverable since the fragmentation data (the file allocation table) was lost.
Finding the save directory
Paths are meaningless when looking directly at the filesystem blocks, so all I have to go off of are the contents of the savedata directory.
Luckily I have a backup so I know what contents I’m looking for, but how do I find it in the raw data?
Metadata blocks are split into 32 byte entries. The first byte of the entry describes what it is:

I am only interested in Type=0x85 (a file and directory entry), which in turn is followed by n other entries:

The entries that follow a directory entry are:
- A stream extension entry (
Type=0xC0), which specifies what the item is and where to find it - 1 or more name entries (
Type=0xC1), which specify the name of the item
Which means a basic directory entry looks like:

Actually, right now I’m only interested in the name entries, since I am looking for a directory containing items with some known names.
Name entries only contain the name of the item encoded in UTF-16-LE:

So I searched for references to a known filename using ripgrep :
>>> "ADRBUBMAN".encode('utf-16-le').hex(' ')
'41 00 44 00 52 00 42 00 55 00 42 00 4d 00 41 00 4e 00'
Search for C1 00 41 00 44 00 52 00 42 00 55 00 42 00 4d 00 41 00 4e 00:
% rg --json --null-data --multiline '(?-u)\xC1\x00\x41\x00\x44\x00\x52\x00\x42\x00\x55\x00\x42\x00\x4d\x00\x41\x00\x4e\x00' vita.img | jq '.data.absolute_offset | select(.)'
98463907904 # 0X16ECE80040
98582429760 # 0X16F3F88040
There are two results because the first of them is the app’s data, while the second one is the save data, this means the save the directory is at 0x16F3F88000 (rounding down to the nearest 32 KiB), so I had a look at the block to find where the saves I’m missing are located:

The numbers mason, what do they mean?!
Stream extension entries don’t point directly at an address, rather they point at a specific block number. To turn this into an address, you simply take the size of the header and add n block lengths:
If I ignore the header, then the Trials of Cold Steel 2 saves are located somewhere around 8.3 GiB (definitely gone), while my FFX saves are located somewhere around 166.7 GiB (should be recoverable).
However, I can’t work out the exact location on account of not having a header.
I have no head, and I must… do maths?
If the equation to get the address of the given block is:
address = offset + block_no * block_size
then offset can be worked out with:
offset = address - block_no * block_size
Therefore, if I can find the address of one file/directory, then I can work out the offset which will let me know the address of any block number.
I ran the game and made a new save (after watching all the unskippable cutscenes again) to get a look at the the file structure:
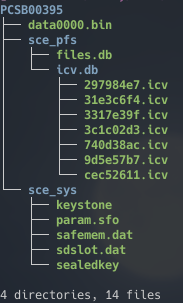
FFX saves (directories are blue, files are green)
Surprisingly, the filename data0000.bin is only shared with Gravity Rush (another PhyreEngine
game). So I repeated the same file name search as before:
% rg --json --null-data --multiline '(?-u)\xC1\x00\x64\x00\x61\x00\x74\x00\x61\x00\x30\x00\x30\x00\x30\x00\x30\x00\x2e\x00\x62\x00\x69\x00\x6e\x00' vita.img | jq '.data.absolute_offset | select(.)'
98582888704 # 0X16F3FF8100
179092979968 # 0X29B2C60100
The first instance is ~91.8 GiB from the start, which is far off the estimated value, while the second one is at ~166.7 GiB, as predicted. Further investigation shows that the first instance matches my Gravity Rush save directory exactly.
The block containing the second instance is at address 0x29B2C60000,
so if I assume that it’s block 5463310, then the offset would be:
offset = address - block_no * block_size
offset = 0x29B2C60000 - 5463310 * 0x8000
offset = 0X43F0000
A combined header and FAT size of ~67.9 MiB sounds reasonable. I also repeated the same steps with other files and got the same offset.
I’m missing data up until 0X3D3A00000, so I can calculate the first valid block number:
offset = address - block_no * block_size
0X43F0000 = 0X3D3A00000 - block_no * 0x8000
block_no = (0X3D3A00000 - 0X43F0000) / 0x8000
block_no = 499394
That means reference to a block number less than 499394 is invalid.
Making a recovery
Using Fox-IT's dissect.fat module , I wrote a quick script to recursively extract a directory starting from the specified sector. It also includes some utility functions that I will make use of later.
You can find it at this Gist: https://gist.github.com/udf/62c24984b89de206fc7ae725cbb9b738#file-extract-py
% python extract.py
writing PCSB00395/sce_pfs/files.db 2048
writing PCSB00395/sce_pfs/icv.db/297984e7.icv 24
writing PCSB00395/sce_pfs/icv.db/740d38ac.icv 2048
writing PCSB00395/sce_pfs/icv.db/3317e39f.icv 2048
writing PCSB00395/sce_pfs/icv.db/9d5e57b7.icv 2048
writing PCSB00395/sce_pfs/icv.db/cec52611.icv 2048
writing PCSB00395/sce_pfs/icv.db/31e3c6f4.icv 2048
writing PCSB00395/sce_pfs/icv.db/3c1c02d3.icv 2048
writing PCSB00395/sce_sys/sealedkey 32768
writing PCSB00395/sce_sys/keystone 32768
writing PCSB00395/sce_sys/param.sfo 32768
warning: skipping fragmented file PCSB00395/sce_sys/sdslot.dat (294912 bytes at 0x29B2CD8000)
writing PCSB00395/sce_sys/safemem.dat 65536
writing PCSB00395/data0000.bin 32768
Looks like sdslot.dat is fragmented. Taking a look at it in a hex editor,
the data looks like it continues for 4 blocks, followed by a block of 0’s, and finally 5 more blocks of data:
Considering that 294912 bytes is exactly 9 blocks long,
I guess that the file was fragmented when part of it was changed. So I combined the fragments:
# sdslot.dat fragmented (looks somewhat contiguous, 4 + NULL + 5)
# sure???
with open('PCSB00395/sce_sys/sdslot.dat', 'wb') as f:
IMAGE_HANDLE.seek(0x29B2CD8000)
f.write(IMAGE_HANDLE.read(CLUSTER_SIZE * 4))
IMAGE_HANDLE.seek(CLUSTER_SIZE, os.SEEK_CUR)
f.write(IMAGE_HANDLE.read(CLUSTER_SIZE * 5))
I then threw the recovered files onto my Vita and:
It works!
(I got insanely lucky)
A trail of cold memes
Searching for the contents of a file lets me find the block number of that file. Then I can search for references to that block number to find the parent directory of the file. With these two ideas in mind, I had a look at the structure of the Trails of Cold Steel saves:
Luckily, there are two files that contain searchable plain text:
sce_pfs/files.db(lists every file, should contain “SAVE000.DAT”)sce_sys/param.sfo(contains the APP ID, “PCSB01016”)
So if I find these files, I can find their parent directories, which would let me recover everything aside from the orphan files marked in red (assuming no fragmentation occurred).
The search continues
Using ripgrep, I searched for the contents of files.db:
% rg --json --null-data --multiline '(?-u)SAVE000.DAT' vita.img | jq '.data.absolute_offset | select(.)'
98145469460 # 0X16D9ED0414
So files.db is located at 0X16D9ED0000, which is block number 2992988 ((0X16D9ED0000 - 0X43F0000) / 0x8000).
A stream extension entry referring to this block would look like:

That’s 0xC0 followed by 19 bytes (7 of which are known to always be 0),
and 2992988 encoded as a 32-byte little endian
integer, which I searched for using ripgrep:
% python
>>> struct.pack('<I', 2992988).hex()
'5cab2d00'
% rg --json --null-data --multiline '(?-u)\xC0.\x00...\x00\x00........\x00\x00\x00\x00\x5C\xAB\x2D\x00' vita.img | jq '.data.absolute_offset | select(.)'
97744650272 # 0x16C2090020
Looking at the block in ImHex I can see that it’s the directory I’m looking for:
it contains two items files.db and icv.db. I recovered it using my script from earlier:
recursive_extract(address_to_cluster(0x16C2090000), 'PCSB01016/sce_pfs')
Luckily no files in this directory were large enough to be fragmented.
Do it again
I repeated what I had done above to recover sce_sys, this time using the expected contents of param.sfo:
% rg --json --null-data --multiline '(?-u)PCSB01016\x00\x00\x00PCSB01016\x00' vita.img | jq '.data.absolute_offset | select(.)'
98145764636 # 0x16D9F1851C
block_no = (0x16D9F18000 - 0X43F0000) / 0x8000
block_no = 2992997
Search for a stream entry that references block 2992997:
% rg --json --null-data --multiline '(?-u)\xC0.\x00...\x00\x00........\x00\x00\x00\x00\x65\xAB\x2D\x00' vita.img | jq '.data.absolute_offset | select(.)'
98145566944 # 0X16D9EE80E0
recursive_extract(address_to_cluster(0x16D9EE8000), 'PCSB01016/sce_sys')
Everything extracted fine, safemem.dat and sdslot.dat were both not fragmented!
We’ve had first recovery but what about second recovery?
I’m still missing the actual save data, but let’s try to decrypt it using psvpfstools and see what happens:
% psvpfsparser -i PCSB01016 -o PCSB01016_out
Missing option --klicensee or --zRIF
sealedkey will be used
using sealedkey...
sealedkey: matched retail hmac
parsing files.db...
verifying header...
header signature is valid
root icv is valid
Validating hash tree...
0 - OK : 31dff601cb1196779b1860af961156297dabc400
1 - OK : c09ba150dc1aca1d73916b392f3a1c856c69a6d5
Hash tree is ok
Building directory matrix...
[WARNING] Directory SCE_SYS size is invalid
Building file matrix...
[WARNING] Invalid file type for file SAVE000.DAT. assuming file is encrypted
[WARNING] Invalid file type for file SAVE001.DAT. assuming file is encrypted
[WARNING] Invalid file type for file SAVE255.DAT. assuming file is encrypted
[WARNING] Invalid file type for file THUMB000.PNG. assuming file is encrypted
[WARNING] Invalid file type for file THUMB001.PNG. assuming file is encrypted
[WARNING] Invalid file type for file THUMB255.PNG. assuming file is encrypted
[WARNING] Invalid file type for file SDSLOT.DAT. assuming file is encrypted
Flattening file pages...
Building dir paths...
Building file paths...
Linking dir paths...
Linking file paths...
File PCSB01016/THUMB000.PNG does not exist
As expected, it can’t find the files I’ve not extracted yet. If I create empty placeholders for all the missing files, the output changes in an interesting way:
Linking file paths...
Matching file paths...
parsing icv.db...
Building icv.db -> files.db relation...
File PCSB01016/SAVE000.DAT is empty
File PCSB01016/SAVE001.DAT is empty
File PCSB01016/SAVE255.DAT is empty
File PCSB01016/THUMB000.PNG is empty
File PCSB01016/THUMB001.PNG is empty
File PCSB01016/THUMB255.PNG is empty
Match found: 74ac119e PCSB01016/sce_sys/sealedkey
Match found: 6207a3d5 PCSB01016/sce_sys/keystone
Match found: 8064324f PCSB01016/sce_sys/param.sfo
Match found: 1d64d8a PCSB01016/sce_sys/sdslot.dat
Match found: 9453ce73 PCSB01016/sce_sys/safemem.dat
Match not found: 120776a8
Now it’s looking for a file that matches a certain hash.
While I could write my own code to search for a block that matches the hash,
Sony uses a Merkle tree
, as well as a custom hash function,
which complicates things, so I’ll stick to letting psvpfsparser do the verification for me.
Brute force is the best force
The names of the files don’t seem to matter to psvpfsparser, if it has the correct data, it’ll be used for the decryption.
Knowing this, I could extract every block to its own file then run the decryption.
Even with ignoring duplicates, there are way too many blocks for this to complete in a reasonable time.
I can narrow down the search space because I know some things about the missing blocks:
- They are not valid metadata
- They are orphans (not referenced by any valid metadata)
- They do not appear in my backups
Finding metadata blocks
Using the type identifier (0x85) and the reserved (0) sections of the file/directory entry,
I can identify the metadata blocks and write them to a file:
Click to show code
import extract
from extract import NUM_CLUSTERS, FIRST_VALID_CLUSTER
from bitarray import bitarray
metadata_clusters = bitarray(NUM_CLUSTERS)
for i, cluster in extract.iter_clusters(FIRST_VALID_CLUSTER):
# guess if its a metadata cluster
if cluster[0] == 0x85 and cluster[6:8] == b'\x00\x00' and cluster[25:32] == b'\x00\x00\x00\x00\x00\x00\x00':
metadata_clusters[i] = 1
with open('metadata.txt', 'w') as f:
f.write(metadata_clusters.to01())
Finding orphans
Using the metadata block list from above, I can find all referenced blocks. Every block that’s not referenced is an orphan.
Click to show code
import math
from bitarray import bitarray
from extract import parse_file_entries, NUM_CLUSTERS
# use metadata cluster list from earlier
with open('metadata.txt', 'r') as f:
metadata_clusters = bitarray(f.read())
referenced_clusters = bitarray(NUM_CLUSTERS)
referenced_clusters.setall(0)
for cluster_no in metadata_clusters.itersearch(bitarray('1')):
entries = parse_file_entries(cluster_no)
# mark every block of contiguous files as referenced
for k, file_ in entries.items():
if file_.stream.data_length == 0:
continue
referenced_clusters[file_.stream.location] = 1
cluster_span = math.ceil(file_.stream.data_length / CLUSTER_SIZE)
if cluster_span >= 2 and file_.stream.flags.not_fragmented:
for i in range(1, cluster_span):
referenced_clusters[file_.stream.location + i] = 1
referenced_clusters.invert()
with open('orphans.txt', 'w') as f:
f.write(referenced_clusters.to01())
Finding unknown blocks
It’s also quite trivial to read my whole backup directory and find every unknown block by hashing them:
Click to show code
import hashlib
from collections import defaultdict
import os
from pathlib import Path
from bitarray import bitarray
import extract
from extract import NUM_CLUSTERS, CLUSTER_SIZE
def walk_files(path):
for root, dirs, files in os.walk(path):
root = Path(root)
for f in files:
yield str(root / f)
def iter_chunks(filename, chunk_size=CLUSTER_SIZE):
offset = 0
with open(filename, 'rb') as f:
while 1:
block = f.read(chunk_size * 1024)
if not block:
return
for i in range(0, len(block), chunk_size):
yield (offset, block[i:i+chunk_size].ljust(chunk_size, b'\0'))
offset += chunk_size
print('reading backup')
file_hashes = defaultdict(list)
for f in walk_files('/booty/misc/backups/vita'):
for pos, chunk in iter_chunks(f):
h = hashlib.sha512(chunk).digest()
file_hashes[h].append((pos, f))
print('reading clusters')
cluster_hashes = defaultdict(list)
for i, cluster in extract.iter_clusters(0):
h = hashlib.sha512(cluster).digest()
cluster_hashes[h].append(i)
known_clusters = bitarray(NUM_CLUSTERS)
for h in (cluster_hashes.keys() & file_hashes.keys()):
for i in cluster_hashes[h]:
known_clusters[i] = 1
known_clusters.invert()
with open('unknown.txt', 'w') as f:
f.write(known_clusters.to01())
I plotted the blocks to see what the candidates look like:
Each pixel is a block, green ones are not in my backups
Out of the 7806338 blocks:
- 4866578 are unique (62.34%)
- 7801042 aren’t metadata (99.93%)
- 4654629 are orphans (59.63%)
- 74391 don’t appear in my backups (0.95%)
Combining all of them gives me 41637 (0.53%) candidates, which is a much more reasonable number of blocks to check.
Cross my heart and hope to decrypt
I dumped all the candidate clusters into the directory and ran psvpfsparser (it took a couple minutes to check all the hashes):
Match found: 74ac119e PCSB01016/sce_sys/sealedkey
Match found: 6207a3d5 PCSB01016/sce_sys/keystone
Match found: 8064324f PCSB01016/sce_sys/param.sfo
Match found: 1d64d8a PCSB01016/sce_sys/sdslot.dat
Match found: 9453ce73 PCSB01016/sce_sys/safemem.dat
Match found: 120776a8 PCSB01016/5463298.32k
Match found: 96c25871 PCSB01016/5463301.32k
Match found: a123efe1 PCSB01016/5463303.32k
Match found: 5d105dd4 PCSB01016/5463306.32k
Match found: 175ba537 PCSB01016/5463311.32k
Match found: 66ff3259 PCSB01016/5463477.32k
Validating merkle trees...
File: 74ac119e [OK]
File: 6207a3d5 [OK]
File: 8064324f [OK]
File: 1d64d8a [OK]
File: 9453ce73 [OK]
Missing sector hash
Now that I know which blocks are part of the save games, I can delete the excess ones:
% mkdir good
% mv PCSB01016/{5463298,5463301,5463303,5463306,5463311,5463477}.32k good/
% rm PCSB01016/*.32k
% mv good/* PCSB01016/
But what does “Missing sector hash” mean?
After some head scratching, I remembered that the 3 thumbnails are 64KiB in size. Perhaps that’s what it’s complaining about?
I can try extending the file to include the next block, this should be correct if there was no fragmentation:
with open('PCSB01016/5463298.64k', 'wb') as f:
f.write(read_cluster(5463298, CLUSTER_SIZE * 2))
Decrypt:
Match found: 74ac119e PCSB01016/sce_sys/sealedkey
Match found: 6207a3d5 PCSB01016/sce_sys/keystone
Match found: 8064324f PCSB01016/sce_sys/param.sfo
Match found: 1d64d8a PCSB01016/sce_sys/sdslot.dat
Match found: 9453ce73 PCSB01016/sce_sys/safemem.dat
Match found: 120776a8 PCSB01016/5463298.64k
Match found: 96c25871 PCSB01016/5463301.32k
Match found: a123efe1 PCSB01016/5463303.32k
Match found: 5d105dd4 PCSB01016/5463306.32k
Match found: 175ba537 PCSB01016/5463311.32k
Match found: 66ff3259 PCSB01016/5463477.32k
Validating merkle trees...
File: 74ac119e [OK]
File: 6207a3d5 [OK]
File: 8064324f [OK]
File: 1d64d8a [OK]
File: 9453ce73 [OK]
File: 120776a8 [OK]
File: 96c25871 [OK]
Missing sector hash
Success! Now I have to repeat those steps for the rest of the thumbnails…
(the hashes seem to only come from the beginning of the file, since adding another 32KiB to them does not change the hash)
Validating merkle trees...
File: 74ac119e [OK]
File: 6207a3d5 [OK]
File: 8064324f [OK]
File: 1d64d8a [OK]
File: 9453ce73 [OK]
File: 120776a8 [OK]
File: 96c25871 [OK]
File: a123efe1 [OK]
File: 5d105dd4 [OK]
Merkle tree is invalid in file PCSB01016/5463311.64k
:(
Excessive force
I guess the last thumbnail is fragmented, so I will have to brute force finding its second block.
Unfortunately, psvpfsparser uses the first file it finds with the correct hash, so I will have to do this externally. Luckily python makes it trivial:
https://gist.github.com/udf/62c24984b89de206fc7ae725cbb9b738#file-try_find-py
What this does is try candidate sector as the second half of the file, until the merkle tree error doesn’t show up.
The successful decryption shows that the second part of the thumbnail at 5463311 was in block 5463475:
Match found: 74ac119e /tmp/tmpt6wzejbs/tmp0w8iq7i7/sce_sys/sealedkey
Match found: 6207a3d5 /tmp/tmpt6wzejbs/tmp0w8iq7i7/sce_sys/keystone
Match found: 8064324f /tmp/tmpt6wzejbs/tmp0w8iq7i7/sce_sys/param.sfo
Match found: 1d64d8a /tmp/tmpt6wzejbs/tmp0w8iq7i7/sce_sys/sdslot.dat
Match found: 9453ce73 /tmp/tmpt6wzejbs/tmp0w8iq7i7/sce_sys/safemem.dat
Match found: 120776a8 /tmp/tmpt6wzejbs/tmp0w8iq7i7/5463298.64k
Match found: 96c25871 /tmp/tmpt6wzejbs/tmp0w8iq7i7/5463301.32k
Match found: a123efe1 /tmp/tmpt6wzejbs/tmp0w8iq7i7/5463303.64k
Match found: 5d105dd4 /tmp/tmpt6wzejbs/tmp0w8iq7i7/5463306.32k
Match found: 175ba537 /tmp/tmpt6wzejbs/tmp0w8iq7i7/5463311+5463475.64k
Match found: 66ff3259 /tmp/tmpt6wzejbs/tmp0w8iq7i7/5463477.32k
Validating merkle trees...
File: 74ac119e [OK]
File: 6207a3d5 [OK]
File: 8064324f [OK]
File: 1d64d8a [OK]
File: 9453ce73 [OK]
File: 120776a8 [OK]
File: 96c25871 [OK]
File: a123efe1 [OK]
File: 5d105dd4 [OK]
File: 175ba537 [OK]
File: 66ff3259 [OK]
Creating directories...
...
failed to find file PCSB01016/5463298.64k in flat file list
Of course it doesn’t know what to do with the extra files that I added, so I have to rename them to match the expected files.
I don’t know what the name of each file should be, so I will just have to guess:
5463298.64k -> THUMB000.PNG
5463303.64k -> THUMB001.PNG
5463311+5463475.64k -> THUMB255.PNG
5463301.32k -> SAVE000.DAT
5463306.32k -> SAVE001.DAT
5463477.32k -> SAVE255.DAT